Das 'Nested Sets' Modell - Bäume mit SQL
Dieses Tutorial beschreibt die 'Nested Sets'-Technik, mit der man solche Bäume mit SQL performant konstruieren kann.

2022-04-01 00:00:00
2022-11-05 00:00:00
gorski@
Das 'Nested Sets' Modell
Bäume mit SQL
Status Quo
Ein häufige Programmieraufgabe ist es baumartige Strukturen abzubilden, also Strukturen in denen jeder Knoten einen Baumes beliebig viele Unterknoten besitzen kann, die jeweils wieder beliebig viele Unterknoten besitzen können etc.
Diese Strukturen kennt jeder, wenn er sich mal genauer Filesystem-Browser (z.B. den Windows-Explorer o.ä), strukturierte Webkataloge oder ähnliche Tools angeschaut hat: Verzeichnisse (Knoten) enthalten Dateien und Verzeichnisse, die ihrerseits wieder Dateien und Verzeichnisse enthalten. Diese Schachtelung erfolgt dabei beliebig tief.
Nun, in Filesystem-Browsern erfolgt die Darstellung rekursiv, da der ganze darzustellende Baum mittels Pointern im RAM offensichtlich schnell genug durchlaufen werden kann. Was ist aber, wenn man aus einer relationalen SQL-Datenbank Daten performant holen möchte, um diese als einen Baum mit z.B. HTML zu visualisieren?
Die mit Abstand schlechteste Idee ist es, verkettete Listen mit Rückwärts- bzw. Vorwärtsreferenzen in der Datenbank zu erzeugen und ebenfalls rekursiv für jeden Knoten eines vermeintlichen SQL-Baumes eine separate Query an die Datenbank abzusetzen.
Solange der darzustellende Baum klein bleibt, werden Performanceverluste nicht augenscheinlich und fallen nicht ins Gewicht, aber bei größerer Datenmengen wird die Datenbank bei diesem Verfahren zwangsläufig in die Knie gehen müssen, da hunderte von Queries den Server verstopfen können.
Merke:
- Nie rekursive Queries an die Datenbank absetzen, wenn es sich vermeiden lässt.
Mit "Nested Sets" (verschachtelten Mengen), einfachen Kenntnissen der Relationalen Algebra und wenig SQL-Verständnis lassen sich binäre und allgemeine Bäume abbilden, ohne dass es im Datenbanklayer zu Rekursion kommen muss. Relationale Algebra ist auch das interne Arbeitsprinzip der meisten SQL-Datenbanken.
Dieses Tutorial beschreibt einen Ansatz für ein Threaded Forum mit Nested Sets in einer abstrakten Form. Den Anfang macht ein visuelles Modell.
Das visuelle Modell
Um einen Baum in einer SQL-Datenbank darstellen zu können, bieten sich sog. "Nested Sets" - verschachtelte Mengen - an. Für das Auslesen einer beliebig tiefen Baumstruktur benötigt man dann nur einen einzigen Datenbank-Query.
Hat man eine Oracle-Datenbank zur Hand, so ist es unnötig auf die hier beschriebene Methode auszuweichen, da Oracle den SQL-Befehl CONNECT BY (PRIOR) beherrscht, und sich somit leicht verkettete Datensätze samt ihrem Grad (Einrückungstiefe, LEVEL) herauslesen lassen. Mehr zu CONNECT BY findet sich in der freundlichen Oracle-Dokumentation.
Ein Baumast mit zwei Blättern läßt sich als Menge folgendermaßen abbilden:
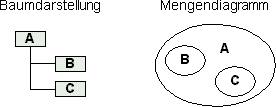
Mengen (Blätter) B und C sind Untermengen der Menge A, also Kinder der Wurzel A. In unseren Beispielen verwenden wir einfachheitshalber nur binäre Bäume - also Bäume mit nur jeweils höchstens zwei Kindern. Selbstverständlich ist die Technik auch auf allgemeine Bäume, deren Knoten wiederum beliebig viele Kind-Knoten enthalten können, anwendbar.
Was hier im Modell offensichtlich ist, muß in einer Datenbanktabelle nicht nur als solches gekennzeichnet werden, es muß auch die Reihenfolge (B vor C) gespeichert werden.
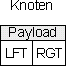
Für diese Speicherung der Abhängigkeit innerhalb einer solchen Struktur benötigen wir zwei Tabellenfelder (im Folgenden LFT und RGT gennant). Die Payload, also die Nutzlast des Knotens beschränkt sich in unseren Beispielen zunächst nur auf einen Buchstaben (A .. n), um die verschiedenen Knoten des Baumes benennen zu können.
Dies sei ein Beispielknoten mit der Nutzlast und dem Zahlenpaar, das die Abhängigkeiten repräsentiert:
Um die Reihenfolge der Knoten zu sichern, speichern wir in den LFT- und RGT-Feldern Zahlen, die uns beim Herauslesen der Daten ermöglichen, mit dem den sog. Preorder-Walk den Baum zu traversieren (zu durchlaufen) - beim Preorder-Walk bedeutet das, dass zuerst der Wurzel-Knoten, dann alle Knoten, die "links" vom jeweiligen Vaterknoten, danach alle Knoten die "rechts" davon liegen, gelesen werden.
Die LFT- und RGT-Zahlenpaare setzen sich für unseren kleinen Beispielbaum folgendermaßen zusammen:
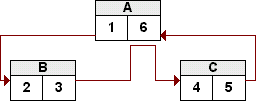
Das Verständnis für die LFT- und RGT-Zahlen ist essentiell, um das Nested-Sets-Prinzip zu erfassen: von der ersten LFT-Zahl (die "1" im Wurzel-Knoten A) ausgehend, wird zuerst das linke Blatt (B) durchlaufen, danach das rechte (C). Bei dieser Traverse - einfach den Pfeilen folgen - wird jeweils eine Zählervariable um den Wert 1 inkrementiert, und zuerst im LFT- und dann nochmals inkremetiert im RGT-Feld gespeichert.
Das zweite Beispiel sieht damit nicht mehr so kompliziert aus:
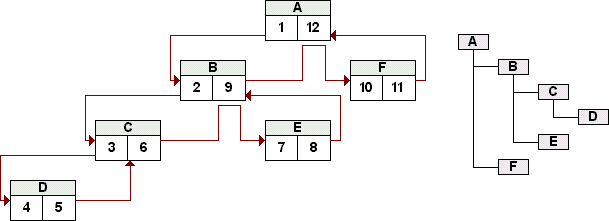
Ausgehend von der Wurzel A wird wiederum jeweils der linke Teilbaum durchlaufen, dann jeweils der rechte. Die LFT- und RGT-Zahlen werden in der vorgebenen Reihenfolge inkrementiert. Besitzt ein Kind-Knoten seinerseits Kinder, so wiederholt sich die Prozedur ebenfalls für diesen Kind-Knoten etc.
Die Reihenfolge des Preorder-Walks ist den Pfeilen oder einfach nur dem Gesetz des Alphabetes zu entnehmen. Dieser Nested Sets-Baum würde in einer seiner Nutzformen den Baum darstellen, der im rechten Teil der Grafik abgebildet ist.
Die Mengendarstellung dieses Baumes könnte folgendermaßen aussehen:
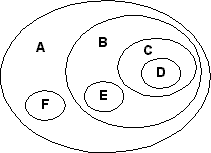
Aufgrund der verschiedenen Zahlenabhängigkeiten kann man sich leicht vorstellen, dass die Nested Sets-Technik sich primär für Strukturen eignet, die nur gelesen werden müssen, z.B. die Darstellung von Forumsbeiträgen oder Katalog- und Menübäumen, da bei jeder Änderung des Baumes alle Abhängigkeiten geändert werden müssen. Bei Forumsbeiträgen oder ähnlichen Bäumen kann man davon ausgehen, das in 95% der Fälle der Zugriff lesend erfolgt.
Bäume die sich öfters dynamisch verändern (müssen) - z.B. Sortierung - werden mit dieser Technik ausgebremst.
Zum hoffentlich besseren Verständnis der Nested Sets-Zahlen hier nochmal ein größeres Beispiel:
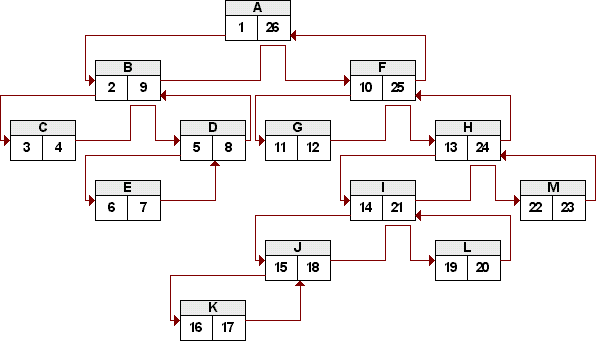
Wer sich diesen Baum genauer anschaut, dem werden mehrere Zusammenhänge der Zahlenpaare klar:
- Wurzel (LFT) = 1
- Wurzel (RGT) / 2 = Anzahl der Knoten im Baum
- Blatt (RGT) - Blatt (LFT) = 1
- Für alle Knoten außer der Wurzel gilt: (Knoten (RGT) - Knoten (LFT) - 1) / 2 = Anzahl der Kind-Knoten
- Alle LFT- und RGT-Werte sind eindeutig
Diese Abhängigkeiten sollte man sich einprägen, sie werden uns später von Vorteil sein.
Der Aufbau eines Nested Sets-Baumes
Als Implementation der Nested Sets mit SQL realisieren wir im Folgenden die Grundstruktur eines "Threaded Forum" also eines Forums in dem Antworten auf ein Posting baumartig dargestellt werden können.
Als Datenquelle für unsere Implementation eignet sich eine beliebige SQL-Datenbank - bei der Überprüfung der Beispiele wurde die schnelle und kostenlose MySQL-Datenbank verwendet. Bei anderen Datenbanken sind die SQL-Statements bzw. -Funktionen (z.B. LAST_INSERT_ID(), ggf. das Locking oder Sequenzen und Trigger anstatt AUTO_INCREMENT) auf die Gegebenheiten der jeweiligen Datenbank anzupassen. Wenn das RDBMS Transaktionen beherrscht (COMMIT, ROLLBACK) sollte man selbstverständlich nicht vergessen diese ergänzend zu den Beispielen zu implementieren.
Unsere simple Thread-Tabelle:
CREATE TABLE node (
node_id INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
root_id INT(10) UNSIGNED NOT NULL,
payload VARCHAR(64) NULL,
lft INT(10) UNSIGNED NOT NULL,
rgt INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (node_id),
KEY root_id (root_id)
);
Um verschiedene Threads (Bäume) voneinander unterscheiden zu können, führen wir in jedem Datensatz die root_id mit. Die root_id ist bei jedem Datensatz, der zu einem Thread gehört, gleich und mit der node_id (dem Primärschlüssel) des allerersten Postings eines Threads identisch.
Die Baumwurzel - das Rootposting:
Die einfachste Operation in unserem Baum ist das Einfügen eines Root- resp. Wurzelpostings. Diese setzt sich aus einem INSERT und einem UPDATE-Statement zusammen. Das UPDATE-Statement wird benötigt, um die bereits erwähnte root_id dem Wert der node_id anzupassen, da der Wert der node_id automatisch vergeben wird (AUTO_INCREMENT bei MySQL) und wir diesen vor der INSERT-Operation nicht kennen können:
LOCK TABLES node WRITE;
INSERT INTO node ( payload, lft, rgt )
VALUES ( 'A - Das Wurzelposting', 1, 2 );
UPDATE node
SET root_id = LAST_INSERT_ID()
WHERE node_id = LAST_INSERT_ID();
UNLOCK TABLES;
Das wenig spektakuläre Ergebnis sieht zunächst folgendermaßen aus:
+---------+---------+-----------------------+-----+-----+ | node_id | root_id | payload | lft | rgt | +---------+---------+-----------------------+-----+-----+ | 1 | 1 | A - Das Wurzelposting | 1 | 2 | +---------+---------+-----------------------+-----+-----+
Ein Wurzelposting ohne Kinder wird immer durch die Zahlen LFT = 1 und RGT = 2 repräsentiert.
Reply - der Baum wird erweitert:
Die Erweiterung des Baumes gestaltet sich ein wenig trickreicher, wenn auch nicht undurchschaubar, wenn man das visuelle Modell der Nested Sets verstanden hat.
Um die korrekte Erweiterung des Baumes zu gewährleisten, kommen ebenfalls mehrere SQL-Statements zum Einsatz. Zwei davon stellen die Integrität der LFT-RGT-Zahlenpaare sicher, das dritte speichert den neuen Datensatz (das Reply) in der Datenbanktabelle ab. Als Eingangsparameter benötigen wir die root_id (nicht die node_id!) - d.h. die Thread-Zugehörigkeit - und die LFT- und RGT-Zahlen des Datensatzes an den der neue Knoten "angehängt" werden soll. Im folgendem Beispiel sind es die Werte:
root_id = 1 (Variable: V_ROOT_ID)
lft = 1 (Variable: V_LFT)
rgt = 2 (Variable: V_RGT)
... also die Daten des Wurzelpostings A. Um den Bezug zum nächsten Beispiel herzustellen wurden diese Werte als imaginäre Variablen (V_ROOT_ID, V_LFT und V_RGT) benannt. Diese Daten müssen vor der Einfügeoperation (z.B. durch ein entsprechendes SELECT-Statement für den zuerweiternden Knoten) ermittelt werden. Da üblicherweise eine übergeordnete Programmiersprache die Steuerung der SQL-Statements übernimmt, dürfte das Beschaffen dieser Werte kein Problem darstellen.
Zusätzlich gewährleistet hier das Locking der Tabellen, dass es zu keiner Zeit zu Kollisionen mir einem anderen Prozeß kommt, der eine ähnliche Einfügeoperation beabsichtigt:
LOCK TABLES node WRITE;
UPDATE node
SET lft = lft + 2
WHERE root_id = V_ROOT_ID
AND lft > V_RGT
AND rgt >= V_RGT;
UPDATE node
SET rgt = rgt + 2
WHERE root_id = V_ROOT_ID
AND rgt >= V_RGT;
INSERT INTO node ( root_id, payload, lft, rgt )
VALUES ( V_ROOT_ID, 'B - Reply auf "A"', V_RGT, V_RGT + 1 );
UNLOCK TABLES;
Spätestens an dieser Stelle wird es deutlich warum sich Nested Sets im Allgemeinen nur für Strukturen eignen, auf die zum größten Teil lesend zugegriffen wird: Die Erweiterung der Baustruktur ist relativ "teuer" - sie kostet viel Zeit, da u.U. sehr viele Knoten eines Baumes verändert werden müssen. Wie teuer so eine Erweiterung des Baumes ist, hängt natürlich von der Komplexität der Struktur ab.
Leider muß in MySQL die komplette Tabelle temporär für den Schreibzugriff gesperrt werden, da uns im Normallfall hier keine Transaktionen zur Verfügung stehen.
Das Ergebnis in der Datenbank:
+---------+---------+-----------------------+-----+-----+ | node_id | root_id | payload | lft | rgt | +---------+---------+-----------------------+-----+-----+ | 1 | 1 | A - Das Wurzelposting | 1 | 4 | | 2 | 1 | B - Reply auf "A" | 2 | 3 | +---------+---------+-----------------------+-----+-----+
Wiederholt man diese "Ergänzungs-Query" ein weiteres Mal mit den Werten LFT- und RGT-Werten des neuen Knotens (B)
root_id = 1 (Variable: V_ROOT_ID)
lft = 2 (Variable: V_LFT)
rgt = 3 (Variable: V_RGT)
mit der Absicht dem Knoten B seinerseits einen Kind-Knoten hinzuzufügen, so erhält man:
+---------+---------+-----------------------+-----+-----+ | node_id | root_id | payload | lft | rgt | +---------+---------+-----------------------+-----+-----+ | 1 | 1 | A - Das Wurzelposting | 1 | 6 | | 2 | 1 | B - Reply auf "A" | 2 | 5 | | 3 | 1 | C - Reply auf "B" | 3 | 4 | +---------+---------+-----------------------+-----+-----+
Als letztes Beispiel fügen wir dem Knoten B noch ein zusätzliches "Reply" hinzu, und beobachten die Änderung in der Datenbank. Das LFT-RGT-Zahlenpaar für den Knoten B hat sich mittlerweile geändert, so dass unsere Ausgangswerte für die Einfügeoperation wie folgt aussehen:
root_id = 1 (Variable: V_ROOT_ID)
lft = 2 (Variable: V_LFT)
rgt = 5 (Variable: V_RGT)
Nachdem die Query ausgeführt wurde finden wir folgendes zufriedenstellendes Ergebnis vor:
+---------+---------+-----------------------+-----+-----+ | node_id | root_id | payload | lft | rgt | +---------+---------+-----------------------+-----+-----+ | 1 | 1 | A - Das Wurzelposting | 1 | 8 | | 2 | 1 | B - Reply auf "A" | 2 | 7 | | 3 | 1 | C - Reply auf "B" | 3 | 4 | | 4 | 1 | D - 2. Reply auf "B" | 5 | 6 | +---------+---------+-----------------------+-----+-----+
Selektieren der Daten
"Wozu der ganze Streß eigentlich?" mag man sich fragen ... Nun, die Früchte unserer Arbeit können wir mit dem folgenden Query ernten:
SELECT node1.payload,
COUNT(*) AS level
FROM node AS node1,
node AS node2
WHERE node1.root_id = 1
AND node2.root_id = 1
AND node1.lft BETWEEN node2.lft AND node2.rgt
GROUP BY node1.LFT;
Dieses Konstrukt gibt den kompletten Thread-Baum mit den Elementen aus, die zu root_id = 1 gehören. Zusätzlich enthalten ist der Grad (level) - so ist es ein Leichtes, korrekte Einrückungen der Threads darzustellen. Das Ergebnis:
+-----------------------+-------+ | payload | level | +-----------------------+-------+ | A - Das Wurzelposting | 1 | | B - Reply auf "A" | 2 | | C - Reply auf "B" | 3 | | D - 2. Reply auf "B" | 3 | +-----------------------+-------+
Als Teil eines Threaded Forums könnte die Ausgabe so aussehen:
- A - Das Wurzelposting
- B - Reply auf "A"
- C - Reply auf "B"
- D - 2. Reply auf "B"
- B - Reply auf "A"
Ähnlich wie beim Erweitern des Baumes benötigen wir für die Ausgabe keinen direkten "Anfangspunkt" (node_id) - es reicht die eindeutige Zuordung (root_id) eines Postings zum Thread, den Rest ergibt die Logik der Nested Sets-Zahlenpaare.
Im normalen Einsatz haben wir trotzdem einen Ausgangspunkt: Üblicherweise wird in einer Übersicht mehr als ein Thread dargestellt. Nach dem Beschaffen der Daten der Wurzelpostings (aller Posting in den root_id = node_id gilt) für eine Übersichtsdarstellung verfügen wir über die benötigten Parameter. Für jedes dieser Wurzelpostings muss zusätzlich die oben beschreibene Operation angewendet werden.
Merke:
- Man könnte auf die Idee kommen, ein komplettes Forum in nur einem Baum mit einer "unsichtbaren" Wurzel zu realisieren, um dann das ganze Forum und dessen Teilbäume (Threads) mit einer einzigen Query herauszulesen. Der gesunde Menschenverstand sollte an dieser Stelle aktiviert werden: Je größer das Nested Set wird, umso teurer ist es neue Einträge einzufügen und umso länger wird das Herauszulesen mittels dem vorgestellten Join dauern.
- Hier gilt es einen Kompromiss zwischen Bequemlichkeit und Geschwindigkeit zu finden, und das Forum in kleinere autarke Teilbäume zu unterteilen.
Mehr Informationen aus dem Baum:
Mit einer leicht veränderten Query können wir für jeden Eintrag die Anzahl der Kind-Knoten ermitteln, und somit bei der Ausgabe die Anzahl der Antworten auf ein Posting angeben:
SELECT node1.payload,
IF ( node1.node_id = node1.root_id,
round( (node1.rgt - 2) / 2, 0),
round( ( (node1.rgt - node1.lft - 1) / 2), 0)
) AS children,
COUNT(*) AS level
FROM node AS node1,
node AS node2
WHERE node1.root_id = 1
AND node2.root_id = 1
AND node1.lft BETWEEN node2.lft AND node2.rgt
GROUP BY node1.LFT;
Das Ergebnis:
+-----------------------+----------+-------+ | payload | children | level | +-----------------------+----------+-------+ | A - Das Wurzelposting | 3 | 1 | | B - Reply auf "A" | 2 | 2 | | C - Reply auf "B" | 0 | 3 | | D - 2. Reply auf "B" | 0 | 3 | +-----------------------+----------+-------+
Selbstverständlich könnte man die LFT-RGT-Zahlenpaare auch direkt aus den Datenbankfeldern rausziehen und die kleine Berechungsoperation in einer übergeordneten Steuerungssprache durchführen.
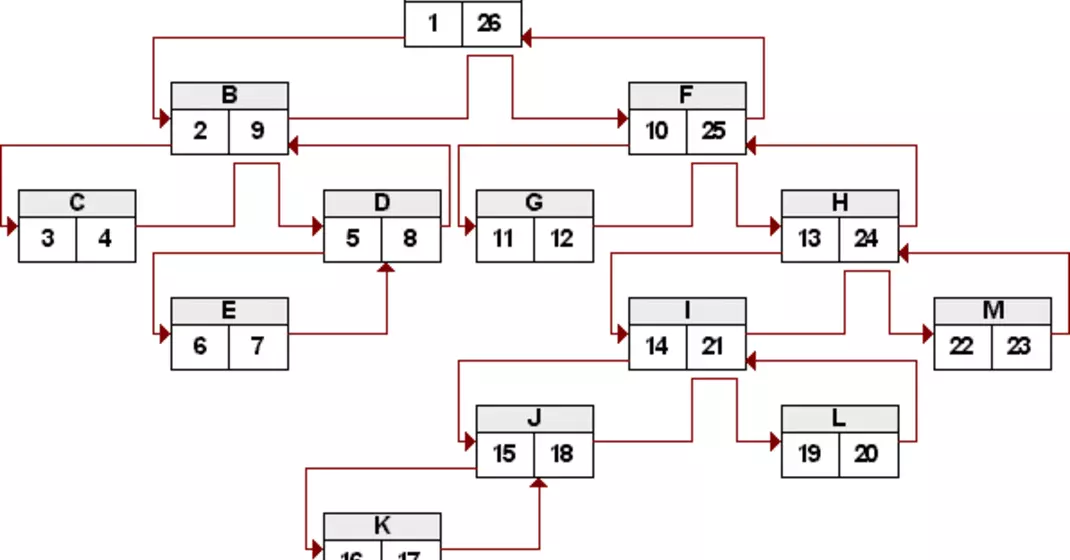
Betrachten wir abschließend das Ergebnis der letzten Query auf einen größeren Baum mit dem Augenmerk auf die jeweilige Einrückungstiefe und die Anzahl der Kinder. Der Baum dürfte bereits aus dem visuellen Modell bekannt sein:
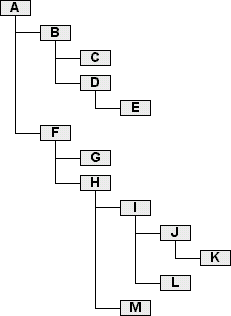
+---------+----------+-------+ | payload | children | level | +---------+----------+-------+ | A | 12 | 1 | | B | 3 | 2 | | C | 0 | 3 | | D | 1 | 3 | | E | 0 | 4 | | F | 7 | 2 | | G | 0 | 3 | | H | 5 | 3 | | I | 3 | 4 | | J | 1 | 5 | | K | 0 | 6 | | L | 0 | 5 | | M | 0 | 4 | +---------+----------+-------+




Verwandte Beiträge
Webseite empfehlen
PHP ermöglicht es dem Besucher mit Hilfe der eigenen mail() Funktion mit wenig Aufwand die eigene Webseite Bekannten oder Freunden weiterzuempfehlen ...

Autor :
Lukas Beck
Kategorie:
PHP-Tutorials
PHP 7 Virtual Machine
Dieser Artikel zielt darauf ab, einen Überblick über die Zend Virtual Machine, wie es in PHP 7 gefunden wird. ...

Autor :
admin
Kategorie:
PHP-Tutorials
E-Mailprüfung mit JavaScript
In diesem Tutorial wird gezeigt, wie eine E-Mailüberprüfung in JavaScript realisiert werden kann ...
Autor :
andy@
Kategorie:
Sonstige Tutorials
HTML5-Formulare mit jQuery.html5form
Mit dem von Matias Mancini machen Sie aus Ihrem Browser einen HTML5-Kompatiblen Bowser. Mit Einschränkungen aber ... ...
Autor :
admin
Kategorie:
Sonstige Tutorials
Konfiguration eines Linux-Rechners als DSL-Router
Dieser Artikel beschreibt wie man unter LINUX einen DSL-Rooter für Windows konfiguriert. ...
Autor :
tschiesser@
Kategorie:
Linux & Server Tutorials

Grundlagen von Views in MySQL
Views in einer MySQL-Datenbank bieten die Möglichkeit, eine virtuelle Tabelle basierend auf dem Ergebnis einer SQL-Abfrage zu erstellen. ...
Autor :
admin
Kategorie:
mySQL-Tutorials



Durchschnittliche Bewertung: